Empowering Users to Verify Twitter’s Algorithmic Integrity with zkml
Last week, Twitter open-sourced their algorithm for selecting and ranking the posts in the “For You” timeline. While this is a major step towards transparency, users cannot verify that the algorithm is being run correctly! One major reason is because the weights for the ML models used to rank tweets have been withheld to protect user privacy. However, these weights are a key factor in determining what tweets show up in each user’s customized feed. Without the weights it is difficult to verify what, if any, biases and censorship may have led to specific tweets being shown, leading to calls to reveal all recommendation algorithms. Can we resolve the tensions between privacy and transparency?
Today, we’ll show how Twitter can prove that the Tweets you’re shown are exactly those ranked by a specific, un-altered version of their ML model using our system zkml! Specifically, we show how to balance privacy and transparency by producing proofs that the Twitter algorithm ran honestly without releasing the model weights. In doing so, Twitter can produce trustless audits of their model.
To accomplish this, we use recently developed tools from cryptography called ZK-SNARKs. ZK-SNARKs allow an algorithm runner to produce a proof that some computation happened honestly — anyone can use the proof to check that the algorithm ran correctly without rerunning the algorithm. In our setting, we’ll focus on the key driver of the decision: the ranking ML model. We’ve previously described how to construct ZK-SNARKs for real-world vision models using our open-source framework zkml, so in this post we will discuss how to use our framework to support this core piece of the Twitter timeline.
In the rest of the post, we’ll describe how Twitter’s “For You” page is generated, how to use zkml to prove the Twitter ranking model executed honestly, and how to use our framework in the broader context of verifying the “For You” page. If you haven’t seen ZK-SNARKs before, our explainer for how ZK-SNARKs can be used for ML may be helpful for understanding the rest of the post!
How Twitter’s “For You” page works
The twitter algorithm operates by collecting data, training a model, and using the model to rank posts to show on your “For You” timeline. At a high level, the algorithm:
- Generates features from user interactions with the site, such as likes and retweets.
- Learns what users would engage with via the ranking model.
- Generates a candidate set of tweets to show to users.
- Ranks the candidate set of tweets using the learned ranking model.
Twitter produced a helpful diagram to show the overall steps:
](https://ddkang.github.io/assets/images/blog/2023-04-17-empowering/fig1.webp)
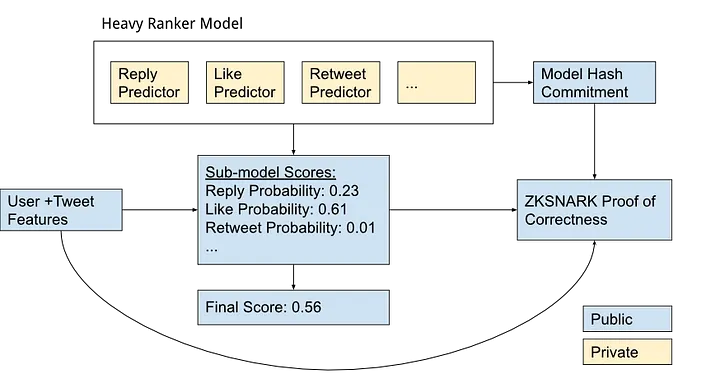
The most important part of the algorithm is the heavy ranker (in the middle), which is the ranking model. Despite the open-source release (including the ranker architecture), users have no guarantees as to what Twitter is running! One way for Twitter to show the algorithm is run in production is to release the weights, training data, and inputs. However, this would violate users’ privacy, so Twitter can’t release the inputs or weights. In order to allow Twitter to prove that their algorithm ran honestly, we’ll turn to ZK-SNARKs.
Using zkml to ZK-SNARK Twitter’s ranking model
As we mentioned, ZK-SNARKs can allow Twitter to prove that the model was run honestly. At a high level Twitter can use ZK-SNARKS to commit to a specific version of their ranking model and then publish a proof that when the model is applied to a specific user and tweet, it produces the specific final output ranking. The model commitment (a model signature or hash), proof, as well as per-user and per-tweet input features can be shared with users. See our explainer post for more details on how zkml integrates with the traditional ML workflow.
Once the proof is made available, there is no need for additional trust for this stage of the algorithm: users can verify on their own that the computations were performed as promised. Furthermore the specific committed ranking model can be audited by third parties without revealing its weights publicly.
To do so with zkml, we can simply run the following commands (after building zkml with the instructions in the README), where model.msgpack contains the model weights and inp.msgpack is the input to the model:
# This constructs the proof, which the Twitter engineer would do.
# For demonstration purposes, we’ve decided to withhold the model
# weights for the time being!
./target/release/test_circuit examples/twitter/model.msgpack examples/twitter/inp1.msgpack
# This verifies the proof with only the open-source model signature,
# which we would do to check our “For You” timeline.
# You don’t need the model to do the verification!
# First, we need to decompress the verification key (see our explainer post for details)
tar -xzvf examples/twitter/vkey.tar.gz -C examples/twitter
# You’ll also need to download the parameters to the directory `params_kzg` from here: https://drive.google.com/file/d/1vesRlcIiMkFdoiISYVUO4RQgY-6-6M6V/view?usp=share_link
# We’ve provided the public values in the repository
./target/release/verify_circuit examples/twitter/config.msgpack examples/twitter/vkey examples/twitter/proof1 examples/twitter/public_vals1 kzg
The actual proofs take a while to generate so we’ve pre-generated them for three examples, which you can verify with the second command. It will take some time to load the data, but the verification itself only takes 8.4ms on a standard laptop!
The final output you’ll see are the probabilities for different sub-model scores that are aggregated into a single final ranking score per tweet. In this example, we’ve converted a trained model and are testing that the circuit evaluates correctly. The actual proofs take a while to generate so we’ve computed them ahead of time here.
What’s important about our framework is that the weights can be hidden while anyone can be convinced from the proof that the execution happened honestly!
Verify your timeline
Now that we can be assured that the ranking algorithm is scoring tweets correctly with zkml, we’ll describe how to use it to verify your timeline. Although the ranking model is the most important component in the algorithm, there are other components that need to be verified as well. We won’t be modeling the other components in this post, but they could be verified by other cryptographic tools, e.g., vSQL or others.
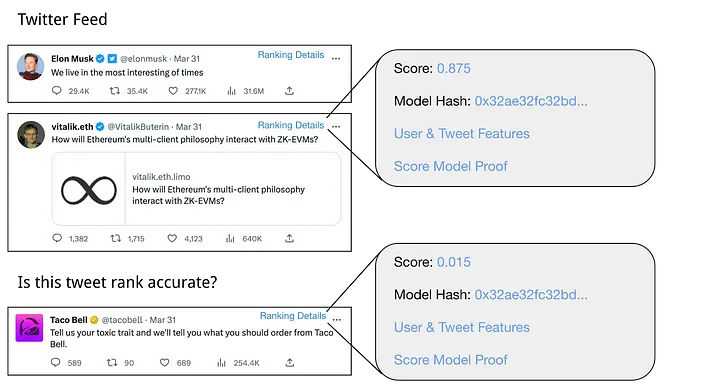
However, there’s still one issue: we need to be assured that Twitter isn’t censoring certain tweets or manually down ranking them. In order to do this, we can “spot check” a given timeline using an interactive protocol.
Let’s say I think my timeline is suspect and that there’s a tweet that I think should rank highly. If Twitter incorporated zkml proofs into their product, I would be able to request proofs of the ranking model execution for tweets in my timeline as well as the suspected censored tweet. Then, I can check to see how the suspected censored tweet ranks compared to the other tweets in my timeline!
If I find that the proof isn’t valid, I’ll have reason to believe that the ranking model (identified by a hash signature in the diagram) Twitter supposedly committed to was altered.
Stay tuned for more!
In this post, we’ve described how to use zkml to verify your Twitter timeline. Our code is open-source and we’re excited to see how it can be used to improve transparency in social media without requiring trust in the complex and opaque systems powering them. Nonetheless, there’s still a lot of work to do to make zkml practical and accessible to everyone. We’ll be working on increasing its efficiency in the coming months.
We’ll also be describing other uses of zkml in the coming weeks — stay tuned! And if you’d like to discuss your idea or brainstorm with us, fill out this form and join our Telegram group. Follow me on Twitter for latest updates as well!