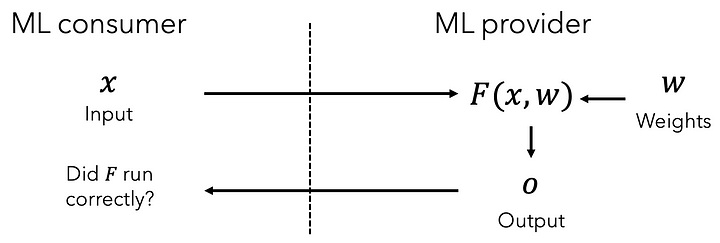
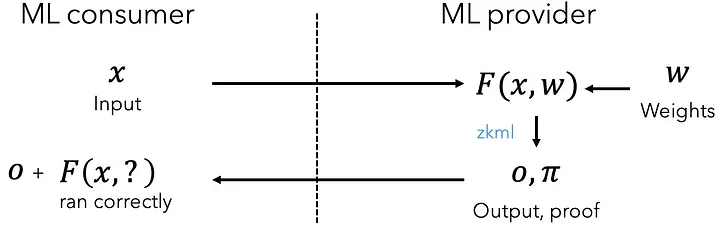
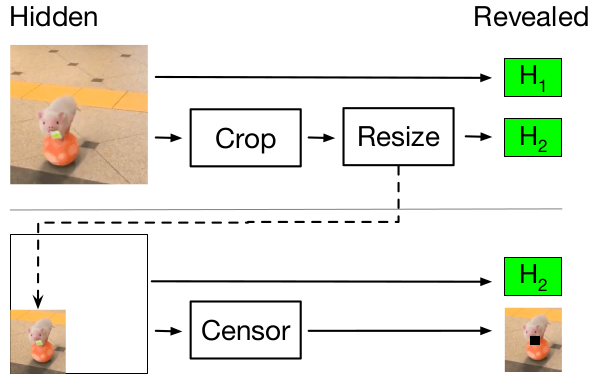
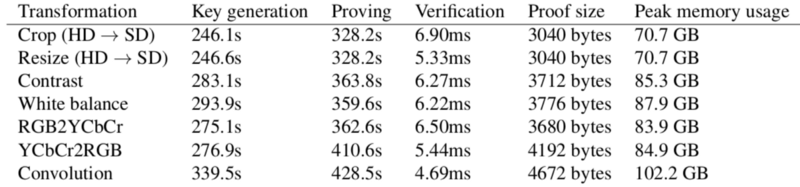
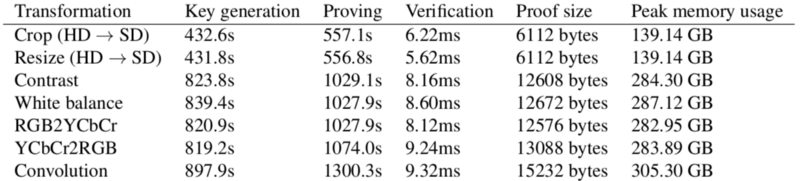
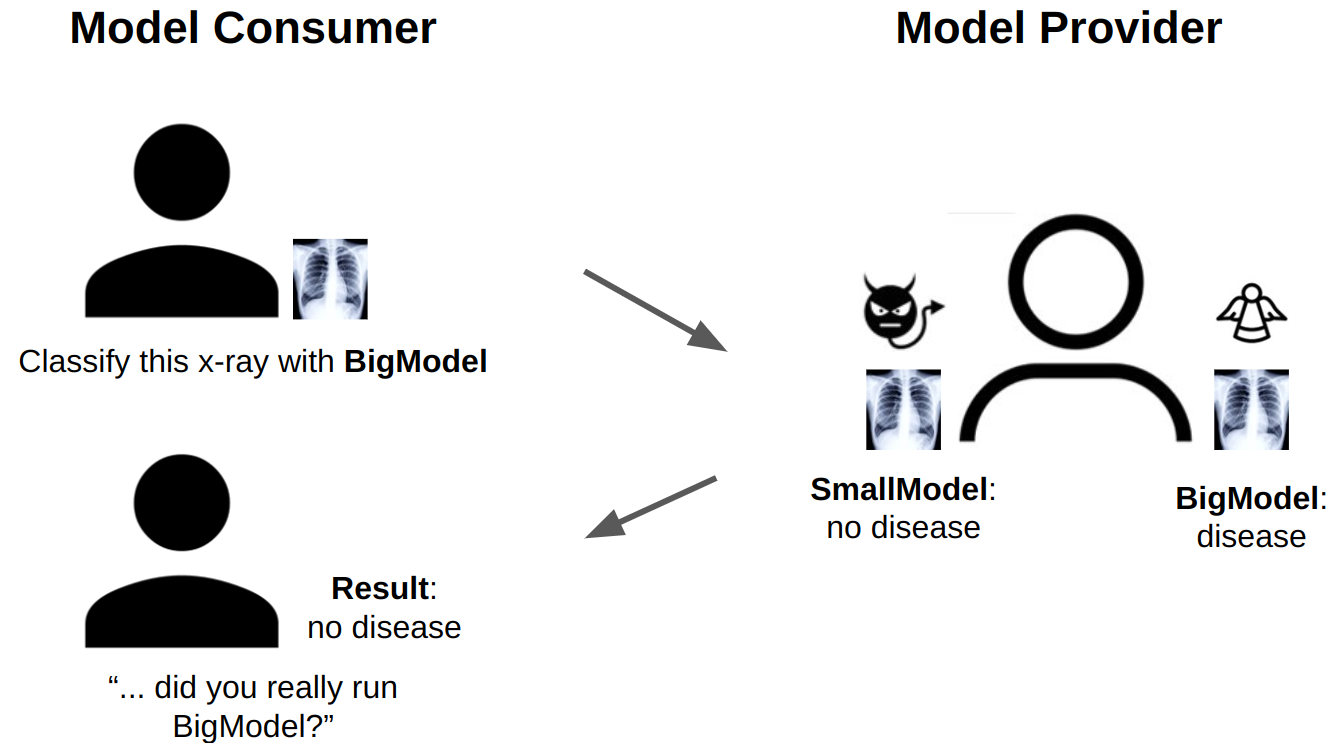
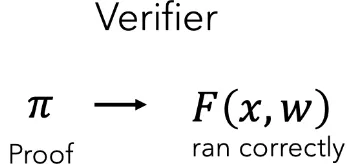In an environment where AI-generated audio can mimic human voices flawlessly, we need a reliable chain of trust stretching from the initial capture of audio to its final playback. This chain of trust can be established using cryptographic technologies: attested microphones for capturing the audio and carried through to the final playback via ZK-SNARKs.
In the remainder of the blog post, we’ll describe how to use these tools to fight AI-generated audio. We’ll also describe how the open-source framework zkml can generate computational proofs of audio edits, like noise reduction. To demonstrate this end-to-end process, we’ve simulated the process of capturing audio to performing verified edits. We’ll describe how we did this below!
Cryptographic tools for fighting AI-generated audio
Establishing a chain of trust from the audio capture to final playback requires trusting how the audio is captured and how the audio is edited. We will use cryptographic tools to establish this chain of trust.
Attested microphones for trusted audio capture
The first tool we will use are called attested microphones. Attested microphones have a hardware unit that cryptographically signs the audio signal as soon as it is captured. This cryptographic signature is unforgeable, even with AI tools. With this signature, anyone can verify that the audio came from a specific microphone. In order to verify that audio came from a specific individual, that person can publish the public key of the attested microphone.
Unfortunately, there’s two limitations of attested microphones. The first (which we will address below) is that attested microphones don’t allow you to perform edits on the audio, including edits like noise reduction or cutting out sensitive information. The second is that these attested microphones currently don’t exist, even though the technology is here. We hope that hardware manufacturers consider building attested microphones to combat AI-generated audio!
ZK-SNARKs for verified edits
Once we have the raw audio, there are many circumstances where we want to privately edit the original audio. For example, intelligence agencies can use background noise to identify your location, which compromises privacy. To preserve privacy, we may want to perform edits like removing the background noise or cutting out parts of an interview that might contain sensitive information.
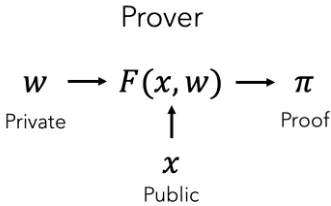
In order to perform these edits, we can use ZK-SNARKs. ZK-SNARKs provide computational integrity. For audio, ZK-SNARKs allow the producer of the audio to privately edit the audio without revealing the original. Similar to cryptographic signatures, ZK-SNARKs are unforgeable, allowing us to extend the chain of trust to edits.
Demonstrating the technology
To showcase the power of attested microphones and ZK-SNARKs, we’ve constructed an end-to-end demonstration of the chain of trust for audio. In our demonstration, we recorded a short 30 second clip, where each of us (Anna, Daniel, and Kobi) recorded on our own microphone. In other words, there are three 30 second clips.
Because attested microphones don’t exist yet, we simulated the attested microphone by signing the individual audio clips with Ethereum wallets. These wallets contain private keys that would be similar to the secure hardware elements in the attested microphone. The signatures we’ve produced are also unforgeable, assuming our wallets aren’t compromised.
During the recording process, Daniel’s microphone picked up some background echo, so we wanted to cut it out and combine the clips into one. We produced a ZK-SNARK that verifies these edits were done honestly from the original audio clips. Furthermore, the ZK-SNARK hides the input audio, so you won’t be able to extract the background noise in Daniel’s clip! This helps preserve privacy.
In the following demo, the final audio file is presented coupled with a proof and a set of signatures. The verification program verifies both, ensuring we know the exact chain of operations performed on the input audio files resulting in the audio you can hear.
Technical deep dive
To understand how our demonstration works at a deeper level, we’ve done a technical deep dive below. You can skip to the conclusion without missing anything!
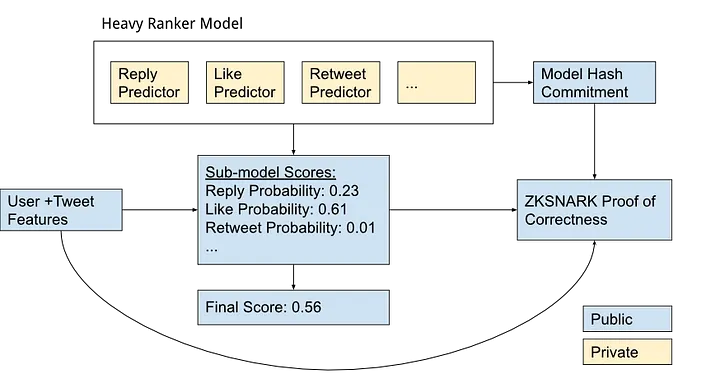
We’ve outlined the overall architecture below:
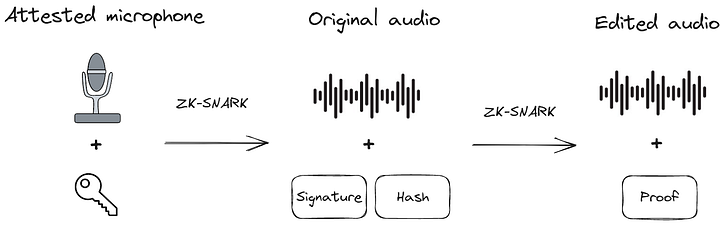
As we can see, the first step (after capturing the audio) is to produce the signatures. Since we don’t have attested microphones, we used Ethereum wallet addresses, which are publicly associated with us (Anna, Daniel, and Kobi), to sign hashes of the original audio. Ethereum uses ECDSA, which allows anyone to verify the signatures we produced with our public key. The private key must remain hidden. In hardware, this can be done using trusted enclaves. The hardware manufacturer can destroy the private key after it is placed on the device. By doing so, the private key is inaccessible!
Given the signed input audio, we want to be able to edit them with computational integrity while preserving the privacy of the original audio. Under the random oracle model of hashing, the hashes reveal nothing about the input. We can combine the hashes with ZK-SNARKs to preserve privacy.
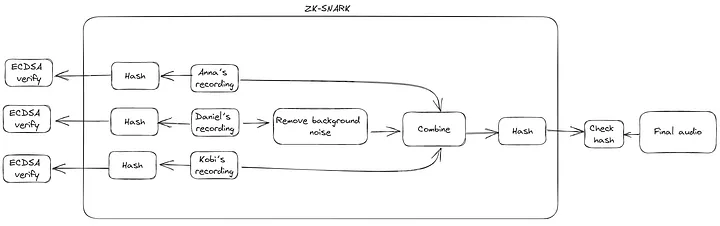
ZK-SNARKs allow a prover to produce a proof that a function executed honestly while keeping parts of the input hidden (and selectively revealing certain inputs or outputs). In our setting, we can compute a function that computes the hashes of the inputs and outputs the edited audio from the inputs. By revealing the hashes, we can be assured that the inputs match the recorded audio! We’ve shown what happens within the ZK-SNARK below:
Conclusions
As we’ve seen, attested microphones and ZK-SNARKs can provide a chain of trust for audio while preserving privacy. With the rise of AI-generated audio, we’re seeing an increasing need to establish this chain of trust. We hope that our demonstration will spur hardware manufacturers to consider building attested microphones.
Stay tuned for more posts on this topic as we delve deeper into other tools to fight malicious AI-generated content. And if you’d like to discuss your idea or brainstorm with us, fill out this form and join our Telegram group. Follow me on Twitter for the latest updates as well!
Important note: the code for this demonstration has not been audited and should not be used in production.
]]>](https://ddkang.github.io/assets/images/blog/2023-04-17-empowering/fig1.webp)